科学研究における観察—仮説—予測—実験ループのパラダイムは、長年にわたり研究者によって科学的発見に向けて実践されてきました。しかし、メガスケールとミリスケールの両方の研究におけるデータ爆発により、科学的発見のサイクルを推進するために、データを手作業で分析し、新しい仮説を提案することが非常に困難になることがありました。
本稿では、科学的発見のための説明可能なAIに基づくパラダイムを示すことにより、科学的発見プロセスにおける説明可能なAIの役割について議論する。鍵となるのは、説明可能なAIを用いて、データやモデルの解釈、仮説、そして科学的発見や洞察を導き出すことを支援することである。計算集約型およびデータ集約型の方法論を、実験的および理論的方法論と組み合わせることで、科学研究にどのようにシームレスに統合できるかを示す。AIに基づく科学的発見プロセスを実証し、人類史上最も偉大な知性を持つ人々に敬意を表すため、16世紀から17世紀の科学革命を牽引したティコ・ブラーエの天文観測データに基づく(説明可能な)AIによって、ケプラーの惑星運動の法則とニュートンの万有引力の法則がどのように再発見されるかを示す。この研究はまた、科学的発見における説明可能なAI(ブラックボックスAIと比較して)の重要な役割を浮き彫りにしています。科学はノウハウだけでなく、なぜノウハウなのかという知識も重要であり、将来起こりうる技術的特異点を人間が回避したり、より良く備えたりするのに役立つからです。
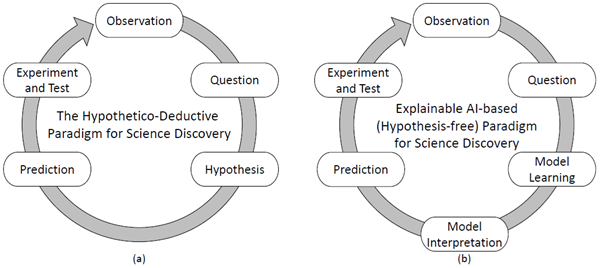
科学研究で頻繁に用いられるパラダイムは、仮説演繹パラダイム(図1(a))であり、長年にわたり研究者によって実践されてきました[1, 2, 3]。このパラダイムでは、研究者はまず観察(通常はデータ収集プロセス)を行い、次に疑問を提起します。疑問への答えを得るために、研究者は通常、帰納的推論プロセスを通じて、観察に対する可能な説明として仮説を提示します。仮説は、研究課題や研究分野に応じて、理論、モデル、方程式、アルゴリズムなど、様々な形式をとることができます。仮説は検証可能な予測を行うために用いられ、その後、実験的検証やデータ分析によって仮説の検証または反証が行われます。上記のプロセスはループとして繰り返される可能性があります。つまり、仮説が偽であると判定された場合、新たな観察を行い、新たな仮説を提案し、さらには新たな質問をする必要が生じる可能性があります。
図1. 科学的発見のための仮説演繹的パラダイム と、科学的発見のための説明可能なAIベース(仮説フリー)パラダイム 新しいパラダイムでは、説明可能なAIを用いて検証可能な仮説を生成します。
科学的発見の好例として、ティコ・ブラーエ、ヨハネス・ケプラー、アイザック・ニュートン(図2)の業績が挙げられます。彼らは人類史上最も偉大な知性を持つ人物であり、16世紀から17世紀の科学革命を牽引しました。ティコ・ブラーエは、正確かつ包括的な天文観測で知られる天文学者でした。16世紀に活躍した彼は、肉眼天文学者でありながら、太陽を周回する惑星の観測が非常に正確だったため、後世の研究者が彼の観測データに基づいて洞察に満ちた発見を積み重ねることが可能になりました。注目すべき人物の一人は、もちろんヨハネス・ケプラーです。彼は後にケプラーの惑星運動の法則として知られる法則を発見しました。科学の発見の過程において、ケプラーは惑星の軌道は太陽を2つの焦点の1つとする楕円であると仮説を立て、ティコの観測データに基づいて火星の軌道方程式を導き出しました。最終的に、この方程式は惑星の将来の位置を予測する上で驚くほど正確であることが判明し、彼の惑星運動の第一法則を証明しました。その後、ケプラーは洞察力に富んだデータの分析を通じて、第二法則と第三法則をさらに発見しました。人類の科学史における最も著名な人物の一人であるアイザック・ニュートンは、惑星がどのように太陽の周りを回るかだけでなく、なぜそのように回るかにも興味を持っていました。つまり、彼の目標は惑星運動の根底にあるメカニズムを説明することでした。この目標を達成する中で、彼は後にニュートンの万有引力の法則とニュートンの運動の法則として知られるいくつかの革新的な発見を成し遂げました。

図2. ティコ・ブラーエ、ヨハネス・ケプラー、アイザック・ニュートンと、科学発見プロセスにおける彼らの役割。
ティコ、ケプラー、ニュートンの業績は100年以上の歴史を誇りますが、科学的発見のプロセスにおいて、観測、分析、そして説明という、それぞれ異なるながらも密接に関連した役割を果たしていることは非常に興味深いことです。ティコの主要な貢献は観測にあり、彼の正確なデータは、将来の洞察に満ちた分析と革新的な発見の基盤を築きました。ケプラーはデータを分析し、そこに隠された意味のあるパターンを発見しました。最後に、ニュートンはそのようなパターンの根底にあるメカニズムを解明し、惑星が他のパターンではなくそのようなパターンで動く理由を示す洞察に満ちた説明を提供しました。よりコンピュータサイエンス的な言葉で言えば、ティコの研究はデータ収集に関するものであり、ケプラーの研究はモデル学習に関するものです。つまり、彼は(現代のコンピュータを使用する代わりに)手動でデータをフィッティングし、そのデータに基づいて予測モデルを学習しました。そして最後に、ニュートンの研究はモデル解釈に関するものです。つまり、彼は(これも手動で)ケプラーの結果に対する概念的および数学的な説明を提供し、ケプラーの法則はニュートンの法則から自然に導き出せるとしました。
現代の科学研究では、様々な機械的、電気的、生物学的機器の助けを借りて、研究パイプラインの多くの要素が自動化されています。最も注目すべき要素は観測とデータ収集です。望遠鏡、センサー、衝突型加速器などの近代的な機器は、研究と発見を支援するためにデータを自動的かつ継続的に収集し、そのような観測データは通常、膨大な量になります。例えば、ハッブル宇宙望遠鏡(HST)は週に最大150GBの空間データを生成し[4]、大型ハドロン衝突型加速器(LHC)実験は年間約90PBのデータを生成します[5]。このように豊富で正確な観測データは、科学研究の最先端を押し広げるのに役立ちますが、同時に、データを処理して洞察に富んだ仮説を構築するという大きな課題ももたらします。しかし、洞察に富んだ仮説を構築することは、新たな科学的発見のための研究サイクルを推進するために極めて重要です。
上記の課題が最新のAIと機械学習技術の助けを借りてどのように軽減できるかを示すために、科学的発見のための説明可能なAIベースの仮説フリーパラダイムを示します(図1(b))。鍵となるのは、手作業による仮説開発をAI主導のモデル学習およびモデル解釈プロセスに置き換えることです。より具体的には、モデル学習コンポーネントは、データ分析、データ拡張、正確な予測モデルの構築にディープラーニングなどのブラックボックスAIツールを採用し、モデル解釈コンポーネントは、ブラックボックスモデルを人間が理解できる形式に変換するためにシンボリック回帰などの説明可能なAIツールを採用し、科学的な意味を理解して科学的洞察を導き出します。この2つのコンポーネントが連携することで、手作業による仮説開発が自動的な仮説開発に変換され、データから洞察に富んだ仮説を構築する労力が節約されます。
説明可能なAIに基づくパラダイムのデモンストレーションとして、ティコの天文観測データに基づく説明可能なAIによって、ケプラーの惑星運動の法則とニュートンの万有引力の法則がどのように再発見されるかを示します。ケプラーの時代には、惑星運動に関する3つの主要な仮説、すなわちティコの理論、プトレマイオスの理論、そしてコペルニクスの理論がありました。これらの3つの仮説は短期的には優れた予測を与えることができますが、長期的には観測データと乖離します。ケプラーは数年にわたる計算の末、最終的にこれら3つのモデルを却下しました。その一方で、彼は楕円軌道仮説を提唱し、それが以前のモデルよりも優れた予測値を持つことを検証しました。このプロセスは、科学的発見における観測-仮説-予測というパラダイムに従っています。私たちの実験は、ケプラーの時代にAIと機械学習技術が存在していたと仮定し、ケプラーが火星の観測データに基づく説明可能なAIベースの科学的発見を用いて、手作業で仮説を立てることなく、どのようにして第一法則と第二法則を導き出すことができたかを示しています。さらに、説明可能なAIは、惑星運動の第一法則と第二法則の発見に役立つだけでなく、ケプラーの第三法則の発見プロセスにも役立ちます。第三法則とは、惑星の公転周期の2乗と軌道長半径の3乗の比は、すべての惑星において一定であるというものです。第三法則を見つけるには他の惑星の観測データが必要なので不可能に思えますが、私たちの実験では、火星のデータのみを使用して、Explainable AIが角速度と太陽からの距離の数値的な関係を非常に高い精度で見つけることができることが示され、第三法則の発見に向けた明確な方向性が示されます。
17世紀最初の30年間、特に惑星運動の3法則が発見されて以来、ケプラーは研究を通じてこれらの法則の運動論的説明を絶えず模索し続けました。彼は磁力に基づいてこれらの法則を説明しようとしましたが、現代の視点から見るとそれは誤りであることが判明しました[6]。しかし、これは人間が「どのように」だけでなく「なぜ」も知りたいという説明への強い欲求を示していると言えます。これが、私たちが科学的発見プロセスにおける説明可能なAIの重要性を強調する理由でもあります。
歴史はアイザック・ニュートンにその説明を求める使命を与えました。惑星の運動の秘密を解き明かすには、力と加速度の概念を活用する必要があります。ケプラーの時代には、科学者たちは力の概念を確立しましたが、力の正確な作用は未だにわかっていませんでした。彼らは、力は距離、つまり速度に比例すると考えていました。ニュートンの偉大さは、力と加速度(速度ではなく)の関係を創造的に結び付け、力と加速度の反二乗の法則を提唱したことにあります。これらの概念に基づくと、ケプラーの法則は、数学的な偏差に基づくニュートンの法則から自然に導き出され、ケプラーの惑星運動の法則の根底にあるメカニズムを説明することができます[7]。
一方、ニュートンは画期的な著作『プリンキピア』で述べたように、力を物理的な観点からではなく数学的な観点から考察し、したがって自身の方法を道具主義的に捉えていた[7]。その結果、彼の数学的枠組みにおける力などの多くの変数に「意味」を付与するのは読者の役割となる。現代の科学者は、ニュートンが変数の意味について独自の洞察力のある理解を持っていたに違いないと考えており、彼の発言は読者の様々な見解に対応するための柔軟性を持たせたものに過ぎないと考えているが、彼の慎重さは、科学的発見における(説明可能な)AIの正確な役割について私たちに考えさせる。説明可能なAIに基づく科学的発見の文脈において、AIマシンは確かに予測のためのブラックボックスニューラルモデルを学習し、予測を説明する記号方程式を学習することができるかもしれない。しかし、マシンは方程式内の変数や変数の組み合わせの「意味」を所有していない。マシンにとって、変数はデータ探索、データフィッティング、予測に使用される単なる記号であり、変数に意味を割り当て、AIマシンによる発見に基づいて宇宙についての理解を構築するのは人間の仕事である1。科学的発見プロセスにおける(説明可能な)AIの役割は、有効な仮説を生み出すこと、あるいは発見を加速するために仮説の探索空間を絞り込むことであるが、発見に「意味」を割り当てる役割は人間(特に分野の専門家)の仕事であり、AIでは代替できない。実験では、楕円軌道を説明する際にAIがどのように力の表現を発見するか、そして力に適切な意味を与えるために人間がどのように介入する必要があるかを示すことで、科学の発見における人間の重要性を実証します。
1 本稿では、人間の視点から見た「意味」に限定して議論する。機械が変数や計算について、人間には理解できない独自の内部「意味」を構築する可能性もあるが、それは本稿の議論の範囲外である。
この研究はまた、科学的発見における説明可能なAI(ブラックボックスAIと比較して)の重要性を浮き彫りにしています。特に、説明可能なAIは、将来起こりうる技術的特異点(または単にシンギュラリティ)を人類が回避したり、より良く備えたりするのに役立ちます。技術の進歩がシンギュラリティにつながる可能性については、ジョン・フォン・ノイマン[8]、アーヴィング・ジョン・グッド[9]、スティーブン・ホーキング[10]など、多くの分野の著名人によって議論されてきました。例えば、I.J.グッドは1965年に、人工知能の進歩によって知能爆発が起こり、知能機械が人間には理解できない方法で問題を解決し、新しい機械を構築することさえできるようになり、人間の知能ははるかに遅れをとるだろうと推測しました[11]。科学的発見という文脈において、ブラックボックスAIを開発し、人間には理解できない複雑なニューラルネットワークなどのブラックボックスモデルを用いて発見や表現を行えるようにした場合(これらのモデルは確かに正確な予測を提供する可能性はあるものの)、機械が人間にはますます理解できない知識を蓄積し、最終的には人間の知識が機械の知識に大きく遅れをとるという状況につながる可能性があります。その結果、人間は科学的発見のプロセスにおいて機械によって生み出される新しい発見や知識を常に把握できるように、AIがそのモデルと発見を人間に理解可能な方法で説明できるようにする必要があります。
本論文の以下の部分では、まず第2節で関連研究を紹介し、次にケプラーとニュートンの研究を例に挙げて、説明可能なAIに基づく科学的発見プロセスを説明します。具体的には、第3節では、本研究で使用するデータと説明可能なAIモデルを紹介し、第4節ではケプラーの法則、第5節ではニュートンの法則を説明可能なAIに基づくパラダイムの下で再発見します。第6節では、議論と今後の方向性を述べて本研究を締めくくります。
説明可能性は多くのAIシステムにおいて考慮すべき重要な視点であり、説明可能なAI(XAI)の研究につながっています。例えば、レコメンデーションシステムは、信頼を獲得し、ユーザーが情報に基づいた意思決定を行えるようにするために、ユーザーに推奨や決定を説明する必要があり、説明可能な推奨に関する研究につながっています[12, 13, 14]。多くの予測アルゴリズムや分類アルゴリズムは、モデル設計者がモデルの動作を理解し、デバッグを改善し、モデルの潜在的なバイアスを検出するのに役立つ説明を提供する必要があります[15, 16, 17]。説明可能なAI手法は、一般的にモデル固有の手法とモデルに依存しない手法に分類できます[12]。モデル固有の手法では、決定と説明の両方が同じモデルによって生成されます。つまり、モデル自体の動作メカニズムは透明であり、モデルによって生成された決定には自然に説明が伴います。モデル固有手法では、決定と説明は通常同時に生成される。モデル固有手法の代表的な例としては、線形回帰 [18]、決定木 [19, 20]、アテンションメカニズム [13, 21, 22, 23] などが挙げられ、これらの説明はそれぞれ回帰係数、決定パス、アテンション重みである。モデル非依存手法では、決定モデルと説明モデルは通常、別々のモデルである。決定モデルは予測と意思決定を担い、説明モデルは決定モデルによって生成された結果を説明する役割を担う。モデル非依存手法では、説明は通常、事後的に生成される。つまり、まずモデルの決定が生成され、次にその決定に対する説明が生成される。モデルに依存しない手法の注目すべき例としては、反事実的説明[14]、局所近似[16]、シャプレー値[15, 17]などが挙げられます。
注目すべきは、説明手法の中には、モデル非依存型とモデル固有型のいずれかに単純に分類できるものではなく、どちらにも実装できるため、非依存型と固有型の中間に位置するものが存在することです。その一例がシンボリック回帰 [24, 25] です。シンボリック回帰は、指定された基底関数から構成される関数 \(f(x_1,x_2, \cdots,x_n)= y\) を見つけ、与えられたデータセットに最も適合する回帰分析の一種です [24]。基底関数には、加算、減算、乗算、除算、べき乗、対数などの基本的な数値演算、正弦、余弦、正接などの三角関数、またはその他の指定された基底関数が含まれます。シンボリック回帰は、データに最適な回帰関数を直接学習するという本質的な方法で行うことも、ニューラルネットワークなどのブラックボックスモデルを最初に学習してデータに適合させ、その後シンボリック関数を用いてブラックボックスモデルを回帰するという不可知論的/事後的な方法で行うこともできます。 シンボリック回帰はNP困難な最適化問題ですが、遺伝的プログラミング[25, 26]、ベイズ法[29]、連続最適化法[30, 31]など、効果的かつ効率的なヒューリスティック手法が開発されています。さらに、産業界や研究においてシンボリック回帰問題を解く需要が高いため、遺伝的プログラミングに基づくEureqa[32]やシミュレーテッドアニーリングに基づくTuringBot[33]など、多くのパッケージやツールキットが開発されています。
科学的発見のためのAIは重要な方向性であり、近年特に注目されています。例えば、創薬[34, 35, 36]、材料設計[37]、化学または物理学の問題[38, 39, 40]のための機械学習の研究には多くの努力が払われてきましたが、多くの研究は実際の観測データではなく、粒子相互作用などの合成データに対して行われています。分子生物学のためのAIに関する最近の注目すべき進歩は、タンパク質の折り畳み構造を予測するための深層学習モデルを開発するAlphaFold[41]です。科学的発見のためのAIに関する既存の研究のほとんどは、AIの説明可能性ではなく、AIの有用性に焦点を当てています。つまり、科学的データのより正確な予測、分類、または回帰のための高度なAIモデルの開発に焦点を当てており、AIモデルやAIに基づく発見の説明にはあまり力を入れていません。しかし、AIが科学的発見に対して洞察に満ちた説明を提供できるようにすることは、研究者がAIモデルの根底にあるメカニズムをより深く理解し、AIモデルが示唆する科学的洞察をより深く理解するのに役立つため、極めて重要であると私たちは考えています。これは、AIによって発見された知識に対する人間の理解を深め、コミュニティにおける科学の進歩を促進するために重要です。
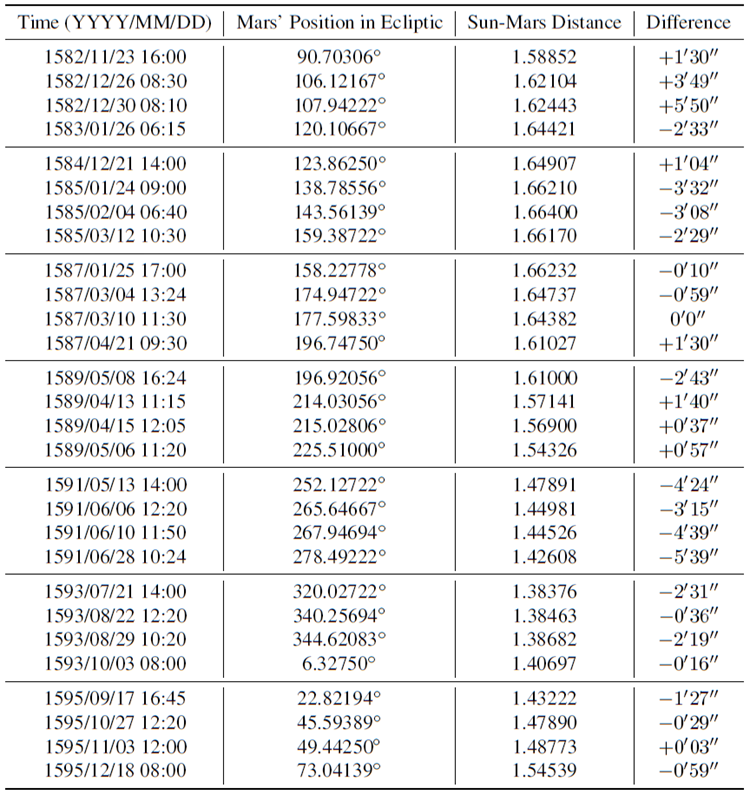
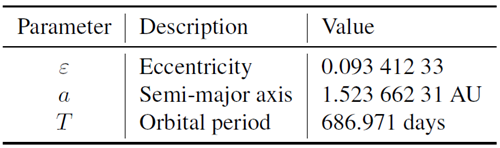
高度な望遠鏡などの現代の研究施設は、太陽を周回する惑星に関する非常に正確で豊富なデータを収集することができます。しかし、ケプラーとニュートンの時代の研究状況を完全に復元し、当時の(限られた)データと知識に基づいて説明可能なAIによってケプラーとニュートンの法則がどのように再発見できるかを示すために、私たちは惑星運動に関する現代のデータを一切使用しません。その代わりに、研究全体を通して、ケプラーが利用可能で使用したデータと知識のみを使用します。これらのデータと知識は、主にティコ・ブラーエによって収集され、部分的に400年前にケプラーによって収集または洗練されました。特に、表1にまとめられているように、ケプラーの画期的な著書「新天文学」[6]に掲載されている、ティコとケプラーによる太陽を周回する火星の観測データを使用します。
表1(付録)では、日付はケプラー2が用いた古い形式で表記されています。グレゴリオ暦の日付を得るには、ケプラーの日付[6]に10日を加えるだけです。太陽からの「火星の角位置」は、ケプラーによって計算された太陽中心黄道座標における火星の経度です。「太陽-火星距離」は、天文単位(AU)を単位としています。ここで注目すべき点は、ケプラーの時代、人類はまだ惑星間の距離をマイルで測定できなかったことです[44, 45]。代わりに、人類は太陽-地球距離の比で距離を記録し、AUの定義と同様に、太陽-地球距離の平均を100,000としました。したがって、ここではAUを単位として使用します3。 「差」とは、地心黄経における火星の位置の計算値と観測値の差です。ティコの観測値の平均測定誤差はわずか数分角で、最大差は6分角未満であるため、このデータはティコとケプラーの観測時点における最高精度のデータとみなします。
2
この古い暦は、ケプラーが用いたユリウス暦に基づいています。ユリウス暦のアルゴリズムによって生じた閏日の増加による春分の日のずれを修正するため、1582年に暦改正が導入され、年間の日数がわずかに調整され、日付が10日早まりました。1582年10月4日は、1582年10月15日と変更されました[42, 43]。これが、現在グレゴリオ暦として知られる暦の始まりです。
3
実際、太陽に対する火星の位置と距離を計算することは、ケプラーの最も天才的な発明の一つです。彼は、火星の周期が687日であり、したがって687日ごとに宇宙の同じ位置に現れるという事実を巧みに利用しました。これにより、三角法に基づいて、太陽と地球の距離(1AU)に対する太陽と火星の距離と方向を計算することが可能になりました[6]。
本研究では、科学的発見においてAIが何ができ、何ができないかを明らかにすることを目指しています。特に、ブラックボックスモデルの学習は物理現象の正確な予測を可能にするものの、自然や宇宙に対する人間の理解を深める上では役立たない可能性があることを明らかにします。データを単なる予測ツールではなく、真に知識へと変換するには、データから学習したブラックボックス予測モデルだけでなく、データとモデルの根底にある物理的な洞察を人間が理解できる方法で明らかにできる説明モデルも必要です。そうすることで、人間はAIの発見のペースに追いつくことができるのです。
私たちの実験では、2種類のモデルを用います。1つは、観測データから学習するニューラルネットワーク(NN)として実装されたブラックボックスモデルです。このブラックボックスモデルは、特定の時刻における火星の位置を予測するなどの正確な予測を行うだけでなく、限られた観測データを科学的発見のための大規模データに変換するデータ拡張も担います。ブラックボックスモデルは、例えば、未来を正確に予測することで暦を作成したり、農業生産を導いたりするなど、人類にとって既に非常に役立っていますが、ブラックボックスという性質上、人間がそのような予測の背後にある物理的メカニズムを理解することは困難です。そのため、私たちは説明のために、ブラックボックスモデルを解釈可能な物理法則を表現する記号関数に変換する記号回帰に基づいて実装された2つ目のモデルを用います。シンボリック回帰プロセスは、データの背後にある物理的なメカニズムに対する洞察に満ちた理解を促す、意味のある物理変数も発見します。
実装の詳細については、NNモデルとして3層の多層パーセプトロン(MLP)を使用し、隠れ層のサイズは100としています。NNはブラックボックスであるため、実験を通してNNの内部構造を変更しません。つまり、異なるデータに適合するために意図的に独自のNN構造を設計することはありません。代わりに、ブラックボックスとしては常に同じシンプルな3層MLPを使用し、ブラックボックスが異なる予測モデルを学習するための入力データと出力データのみを指定します。モデルの説明には、シミュレーテッドアニーリングに基づく広く使用されているシンボリック回帰アルゴリズムであるTuringBot [33]を使用します。このアルゴリズムは、物理学に着想を得たさまざまな学習問題で優れたパフォーマンスを発揮しています[46]。
まず、ケプラーが第一法則を発見した過程を振り返ってみましょう。ケプラーの時代には、惑星の運動にはプトレマイオス理論、コペルニクス理論、ティコ理論の3つのモデルがありました。ケプラーは著書『新天文学』[6]の中で、これら3つのシステムはいずれも短期的には高い予測精度を示すものの、長期的には過去の観測結果や将来の観測結果と乖離し、適合しないと述べています。彼の研究の第一歩は、観測データの精度を確認することでした。理論が不正確な観測に基づいている場合、その理論は誤解を招く可能性があります。そのため、ケプラーは少なくとも70回の検証を経た計算を行い、多大な時間を浪費しました[47]。今日でも、データの収集と検証は依然として重要かつ必要ですが、比較的成熟しており、その大部分は最小限の手動介入で自動的に行うことができます。
ケプラーは複数回の再計算を経て、ティコの観測データを信じることを選択した。しかし、既存の惑星運動モデル[48]の測定誤差に満足せず、惑星の軌道は太陽を2つの焦点の1つとする楕円であるという新しい仮説を提唱した。これはケプラーの惑星運動の第一法則として知られ、彼は観測データを用いてこの仮説を検証した。このプロセスは、科学的発見における伝統的な仮説演繹的パラダイムを実践したもので、仮説は最初に手動で提案され、次に仮説を検証または反証するための実験が実行される。以下では、データから直接ケプラーの法則を再発見する、(説明可能な)AIに基づく仮説フリーの科学的発見プロセスを示す。
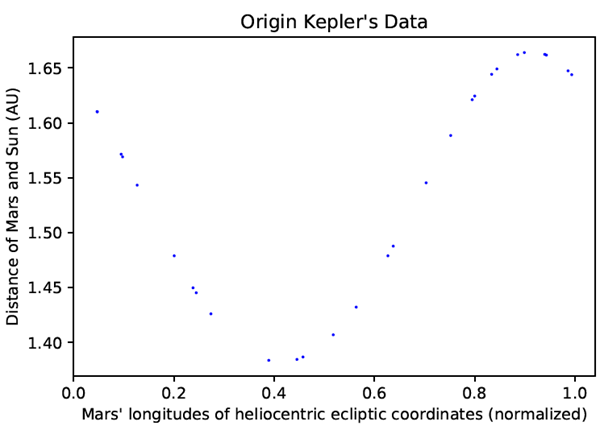
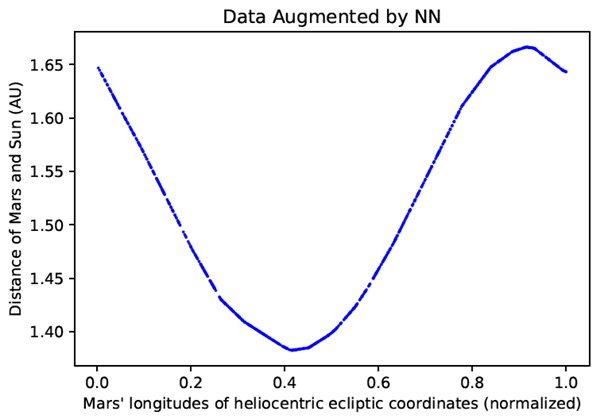
まず、ニューラルネットワークモデルをブラックボックスモデルとして用いて、データのフィッティング、予測、データ拡張を行います。ディープニューラルネットワークの利点は、少量の観測データを大量のデータサンプルに拡張し、AI による科学的発見を促進するために、データをスムーズにフィッティングできることです。表1の観測データポイントを図3にプロットします。元の観測データの量が少ないため、検証には3つのサンプルのみを使用し、残りの25のサンプルを学習に使用します。 \(NN\) ベースのデータフィッティングを用いて回帰関数 \(r=NN(θ)\) を学習するためのトレーニングエポック数を200,000に設定しました。ここで、NNは学習済みのニューラルネットワーク関数、rは太陽と火星間の距離、\(θ\) は太陽に対する火星の角度位置です(表1の2列目と3列目)。トレーニングデータと検証データにおけるNNの最終的な平均二乗損失(MSE)はそれぞれ \(4×10^{-11}\) と \(7×10^{-8}\) であり、ニューラルネットワーク関数が非常に正確な予測を提供できることを意味します。データ拡張のために、\(NN\)モデルの入力範囲と同じ範囲にある0から1までの乱数を 1,000 個均一にサンプリングし、\(NN\) モデルに入力する。次に、サンプリングした入力と対応する \(NN\) モデルの出力を用いて拡張データサンプルを生成し、関数を近似する。拡張データサンプルは図4に示している。
次のステップは、シンボリック回帰に基づいてニューラルネットワーク関数\(r = NN(\theta)\)を人間が理解できるシンボリック関数に変換し、ブラックボックスモデルから物理的な洞察を得ることです。図4から、NNモデルは滑らかな関数近似の能力に優れており、データの周期性も確認できます。しかし、この3層MLPモデルはAIの観点からは非常にシンプルですが、依然として非常に複雑な非線形ネストされた行列乗算式であり、その物理的な洞察を理解するのは困難です。そのため、Explainable AIとしてシンボリック回帰を用いて、ブラックボックスモデルをシンプルで直感的な物理ルールに変換します。特に、ニューラルネットワーク関数\(r=NN(\theta)\)を明示的なシンボリック関数\(r=f(\theta)\)に変換したいと考えています。シンボリック回帰では、周期性を考慮し、余弦関数(cos)を、加算(+)、乗算(\(\cdot\))、除算(/)(減算は負の符号を付加することで表すことができます)という3つの基本演算とともに使用します。シンボリック回帰の結果を表2に示します。
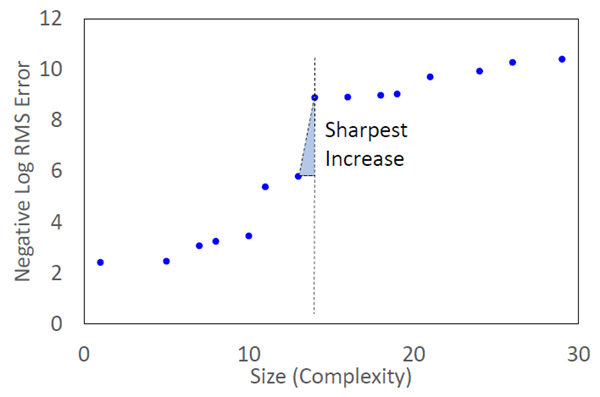
表2において、誤差はブラックボックスモデルの出力とホワイトボックスモデルの出力との間の二乗平均平方根誤差(RMSE)を意味し、\(RMSE =\sqrt{\sum_\theta (NN(\theta)−f(\theta))^2}\)となります。サイズは生成された関数の複雑さを表し、生成された関数で使用される各基本関数のサイズを合計することで計算されます。各基本関数のサイズは表3に示されています。シンボリック回帰プロセスでは、単純で効果的な関数が選択されます。つまり、より単純な(サイズの小さい)関数が複雑な(サイズの大きい)関数よりも正確(誤差が小さい)である場合、複雑な関数は結果から除外されます。図5は関数のサイズと負の対数誤差の関係をプロットしたものです。サイズ14の候補関数は、サイズを小さく保ちながら、精度(負の対数誤差の観点から)が最も急激に向上していることがわかります。これは、この関数が、データの背後にある物理的法則を明らかにするために、精度と複雑さの間の良好なバランスを達成する可能性が最も高いことを示しています[30]。 この関数を式(1)のように書き直して簡略化します。 \[ \begin{align} r=f(\theta) &= \frac{1.51977}{ 1.00625+0.0932972·\cos(θ+0.544536)} \\ \\ &=\frac{1.51033}{1+0.0927177·\cos(θ+0.544536)} \tag{1} \end{align} \] 楕円方程式の基礎知識があれば、式(1)は標準的な楕円軌道を意味し、それは極座標で次の関数として表されることがわかります。 \[ r=f(\theta)=\frac{l}{1+ε·\cos(\theta)} \tag{2} \] ここで、\(r\)は太陽と火星の間の距離、\(θ\)は太陽中心の黄道座標における火星の経度です。 これは、火星の軌道が太陽を焦点とする楕円であることを明確に示しており、ケプラーの第一法則につながります。次の節では、式(1)の数値の意味をさらに解釈します。
楕円軌道に加えて、式(1)からより深い洞察が得られる。ケプラーの著書『新天文学』[6](第41章、321ページ)では、複雑かつ綿密に設計された幾何学的計算に基づき、火星の離心率が0.09264と算出されている。式(1)と式(2)の2つの式を比較することで、火星の離心率が\(ε=0.0927177\)であることが直接わかる。これは、ケプラーの結果と相対誤差0.1%未満で一致する傾向がある。 Explainable AI ベースの結果を、現代科学観測による火星の離心率(表 4 参照)と比較すると、相対誤差は約 0.7% であり、ケプラーの結果と比較した場合よりも大きいことがわかります。これは、400 年前に収集されたティコとケプラーのデータの観測誤差によるものと考えられます。しかし、相対誤差は依然として小さく、ケプラーと同じデータを使用しているため、結果は妥当です。したがって、私たちの結果がケプラーの結果に近くなるのも当然です。
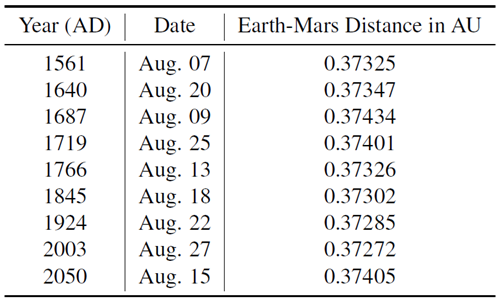
式(1)と標準的な楕円方程式とのもう一つの違いは、余弦関数の偏角です。標準的な楕円方程式では\(r_{min}= f(θ=0)\)ですが、私たちの式では\(r_{min}=f[θ=-0.544536(約-31.2^\circ)]\)です。これは、歴史上最も接近した火星の衝の系列と一致しており、それによって説明できます。火星の衝とは、地球が太陽と火星の間を通過する現象です。表5([49]より)は、1500年代(ケプラーの時代)から現在に至るまで、火星と地球の距離が0.375 AU未満であったすべての最も近い火星の衝を示しています。これらの火星の最接近はすべて8月頃に発生しており、これは秋分(9月23日頃)の約1か月前、つまり太陽が天の黄経 \(180^\circ\)、つまり \(\theta_{Earth}=0\) に達する時です。地球の軌道は円に非常に近いため(ケプラーの時代の科学者たちは観測によってこれを知っていました [6][p.271-272])、火星の接近時における火星と地球の距離は主に火星の位置によって決まり、火星の最接近に関する過去の観測結果(例えば表5)によれば、火星は8月頃に近日点にある可能性が最も高いと考えられます。これはExplainable-AIモデルによって示された結果と一致しています。なぜなら、式(1)は、\(\theta_{地球}=\theta_{火星}=-0.544536\approx -31.2^\circ\)のとき、8月が火星の近日点であるとも示しており、これは秋分点の約\(\frac{31.2}{360}×365≈32\)日前、つまり8月だからです。以下では、Explainable-AIに基づいてニュートンの法則を追求する過程で、ケプラーの他の法則がどのように発見されるかについても示します。
ケプラーの第一法則と火星の特定の特性を、Explainable AIによってデータから抽出できることを示しました。しかし、これでは満足できないかもしれません。なぜなら、火星がなぜ楕円軌道を描いて公転するのか、そしてこの楕円軌道を駆動する「力」は何なのかを知りたいと思うのは当然だからです。歴史的に、限られた情報とツールのもと、ケプラーは太陽と火星の距離が変動するのは、太陽による火星の磁気的な引力と反発によるものだと考えました[50]。これは、イギリスの医師で物理学者のウィリアム・ギルバートが1600年代初頭に出版した画期的な著書『磁石論』の中で、地球は磁石であるという提唱に触発されたものです[51]。現在ではこの説明が真の理由ではないことが分かっていますが、ケプラーが使用した古代のデータに基づいて、Explainable AIがこの疑問に答えるのに役立つかどうかは想像に難くありません。
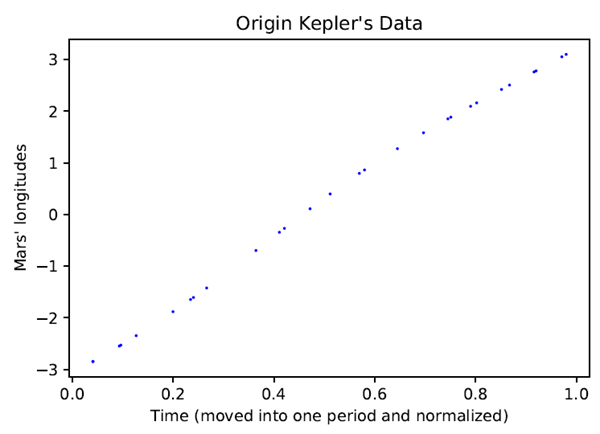
式(1)は、太陽に対する火星の位置を\(r=f(\theta)\)と表しています。表1では時間情報を使用していないため、火星の位置と時間の関係を構築することは直感的で興味深いアイデアです。より具体的には、\(\theta-as-t\)関係\(θ= g(t)\)が得られることを期待します。したがって、\(r=f(\theta)\)関数と組み合わせることで、将来の任意の時点における火星の位置を予測できるようになります。これは、ケプラーとニュートンの時代における天文学と暦の発展にとって重要な問題でした。また、正確な未来予測を行うことは、理論が正しいかどうかを検証するためにも重要です。ケプラーと同時代の科学者たちは、火星の公転周期が約687日であることを知っていました。表1のデータの期間はそれよりもはるかに長いため、すべてのデータ点を1つの公転周期にシフトし、時間を[0,1]の範囲に正規化して視覚化しやすくしました。正規化された時間\(t\)と火星の経度\(θ\)を図6に示します。\(\theta-t\)の関係は線形に近いものの、ある程度の非線形性があり、これは火星が太陽を周回する際に速度がわずかに変化することを示唆しています。
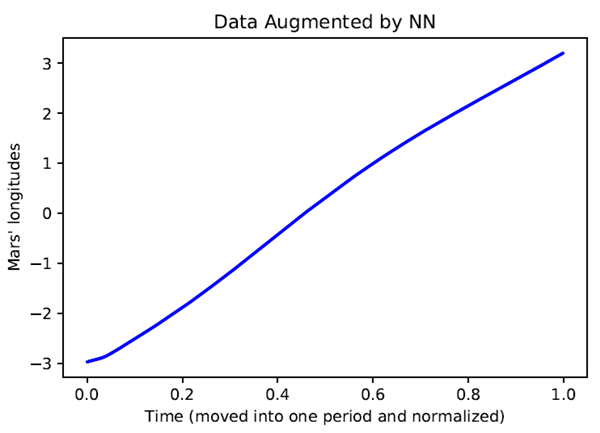
以前の実験と同様に、まずデータをニューラルネットワークモデルに入力し、ブラックボックス予測とデータ拡張を行います。予測器 \(θ=NN(t)\) を学習させるために、単純な3層の多層パーセプトロン (MLP) ネットワークを使用します。ここで、入力は正規化された時間 \(t\)、出力は火星の経度 \(θ\) (ラジアン) です。200,000 エポックの学習後、学習データと検証データの平均二乗損失 (MSE) はそれぞれ \(7\times 10^{-8}\) と \(1.5\times 10^{-5}\) です。トレーニング後、データ拡張の入力として0と1の間の\(2T\)点を均一にサンプリングします。ここで、\(T=687\)は火星の公転周期です。図7に、トレーニング済みのニューラル予測器\(θ=NN(t)\)に基づいて拡張されたデータポイントをプロットします。
実際、ブラックボックスニューラル予測器 \(θ=NN(t)\) を学習するために機械学習を採用した上記の単純な実験は、科学的発見における機械学習(特にニューラルネットワークに基づく深層学習)の重要な役割を示唆しています。今日では、高度な数学的ツールと惑星運動のより深い理解に基づいて、\(t\) と \(θ\) の関係は次の式(3) で表せることが分かっています [52]。 \[ \frac{2\pi}{T}t=2\tan^{-1}\left(\sqrt{\frac{1-\epsilon}{1+\epsilon}}\tan\left(\frac{\theta}{2}\right)\right)- \frac{\epsilon\sqrt{1-\epsilon^2}\sin(\theta)}{1+\epsilon\cos(\theta)} \tag{3} \] ここで、\(T\)と\(\epsilon\)は火星の定数パラメータです。これは、\(t\)を\(\theta\)の関数として、つまり\(t=h(\theta)\)と表すことができることを意味します。しかし、式(3)は超越方程式であるため、\(θ\)を\(t\)として、つまり\(θ=g(t)\)と表す関数を見つけることは困難です。その結果、式(3)を知らないと仮定すると、\(\theta-t\)関係を見つけるのに労力を費やすことになるでしょう。しかし、\(\theta-t\)関数\(θ=g(t)\)を見つけようとする試みは、手作業であれ、記号回帰などの自動ツールであれ失敗し、時間の無駄になります。しかしながら、火星の運動の重要な特徴、例えば角速度や加速度などを解析したい場合、\(\theta-as-t\)関数が必要になることもあります。ディープラーニングとニューラルネットワークモデルは、この問題の解決策を提供します。普遍近似定理[53, 54, 55]によれば、ニューラルネットワークは、構造と重みが適切に設計され学習された場合、学習データに基づいて広範囲の関数を近似できるためです。その結果、\(θ=g(t)\) の関数形を見つけるのは(そもそも可能だとしても)困難であるにもかかわらず、ニューラルネットワークとしてかなり良好な \(\theta-t\) 関数を学習することができ、\(θ=NN(t)\) は微分可能であるため、角速度 \(ω=\frac{dNN(t)}{dt}\) や角加速度 \(a=\frac{d^2NN(t)}{dt^2}\) などの \(\theta-t\) 関係について数学的解析を行うことができます。これにより、他の方法では計算が困難な多くの物理変数間の物理的な関係を発見することが可能になります。この点については、以下の節でさらに詳しく説明します。
ケプラーの時代には微積分はまだ発明されていませんでしたが、科学者たちはすでに速度の概念を確立していました。 そのため、角速度を導くために微分を用いるべきではありませんが、前の節で学んだブラックボックス型ニューラルネットワーク予測モデル\(θ=NN(t)\)に基づいて、ある時間間隔内の角度\(θ\)の変化を計算することで、角速度\(ω\)を計算できます。 ニューラルネットワークモデルの一般化能力を示すために、火星の1公転周期である0.1から0.9までの異なる値(\(t_i (i=1, 2, 3, 28)\)と表記)を用いて、\(θ=NN(t)\)から同じ数(28)のデータ点をランダムにサンプリングします。各 \(t_i\) について、ニューラルモデルを用いて火星の角度 \(\theta_i = NN(t_i)\) を取得します。 次に、時間間隔 \(\delta_t = \frac{1}{32}\) 日(約 45 分)を設定し、各時刻 \(t_i\) について、対応する角速度 \(\omega_i =\frac{NN(t_i+\delta_t)-NN(t_i-\delta_t)}{2\delta_t}\) を計算します。さらに、式 (1) に基づいて、時刻 \(t_i\) における対応する太陽-火星距離 \(r_i=f(\theta_i)=f(NN(t_i))\) も取得できます。
さて、拡張データポイント \((t_i, \theta_i, r_i, \omega_i)\) を使用して、これらの物理変数の一部またはすべての間に、解釈可能なシンボリックな物理的関係を見つけたいと考えています。 今日では高校生でさえそれらの関係を知っていますが、シンボリック回帰などの説明可能なAIを使用してそれらの関係を見つける際には、根底にある物理的ルールについての知識はないと想定する必要があります。なぜなら、このタスクにおける説明可能なAIの役割と能力を示すためには、発見プロセスに事前知識を導入することを避ける必要があるからです。その結果、既存の変数から想像できる限り多くの変数を拡張し、既存の変数と拡張された変数の両方を含む、一部またはすべての変数の根底にある潜在的な関係を見つけるために、シンボリック回帰に完全に依存します。
このプロセスのデモンストレーションとして、\(r\) と \(ω\) の関係を見つけようとします(必要に応じて、他の変数のペアにも同じプロセスを適用できます)。また、べき乗演算の複雑さを軽減するために、\(r_2=r^2, r_3=r^3\) や \(\omega_2=\omega^2, \omega_3=\omega^3\) などの拡張変数を作成します。最後に、\(r_1 =r, r_2=r^2, r_3=r^3\) をそれぞれシンボリック回帰 \(\omega_1=\omega, \omega_2 =\omega^2\) と \(\omega_3=\omega^3\) の入力変数として使用し、次に、このプロセスを逆順に繰り返します。つまり、\(\omega_1=\omega, \omega_2=\omega^2, \omega_3= \omega^3\) をそれぞれシンボリック回帰 \(r_1=r, r_2=r^2\) と \(r_3 =r^3\) の入力変数として使用します。前回の実験と同様に、記号回帰には4つの基本演算、すなわち余弦(cos)、加算(+)、乗算(\(\cdot\))、除算(/)を使用します。このプロセスにおいて、\(\omega_2 = F(r_1, r_2, r_3)\)の関数を求める際の記号回帰結果は表6に示され、関数のサイズと回帰誤差(負の対数RMSEで表したもの)の関係は図8に示されています。
図8から、サイズ4の関数の精度が最も急激に向上していることがわかります。これは、この関数がデータの背後にある物理的な法則を明らかにするために、精度と複雑さのバランスをうまく取れる可能性が最も高いことを示しています[30]。この関数を次のように書きます(\(\omega_2=\omega^2, r_3=r^3\) であることを思い出してください)。 \[ \omega^2=\frac{0.000298491}{r^3} or r^3\omega^3 = c =0.000298491AU^3day^{-2} \tag{4} \] 現代科学の知識に基づくと、\(r^3\omega^2=GM\) であることが分かっています。ここで、\(G=6.674×10^{-11}m^3kg^{-1}s^{-2}\) は重力定数、\(M=1.989×10^{30}kg\) は太陽の質量です。また、距離の単位は \(1AU=1.496×10^{11}m\) なので、\(r^3\omega^2=GM =2.96×10^{-4}AU^3day^{-2}\) となり、この数値は式(4)の定数に非常に近く、相対誤差は約0.8%です。これは、400年前に収集された古代のデータのみを使用したことを考えると小さく妥当な値です。これは、データの背後にある物理的なルールを発見するシンボリック回帰などのExplainable AIの優れた能力を示しています。
(説明可能な)AIは正確な予測を行い、説明可能な方程式を生成できることを示しましたが、AIアルゴリズムや機械は科学的発見プロセス4で出現する物理的な変数や規則を「理解」したり「意味」を生み出したりするわけではないことを強調しておきたいと思います。AIや機械の観点から見ると、変数や規則は単なる記号や方程式であり、AIアルゴリズムはデータ分析を行い、刺激的な変数や規則を抽出する役割のみを担っています。一方、人間の役割は、それらを理解し、抽出された変数や規則に意味を与えることです。例えば、AIアルゴリズムは、全体としてデータの予測と説明に特に役立つ新しい変数の組み合わせを発見するかもしれません(詳細は後述します)。この場合、人間の専門家は、この変数の組み合わせの物理的な意味を解釈し、それを活用して問題をより深く理解しようとするかもしれません。場合によっては、人間の専門家が、結果をより適切に解釈し、人間とAIが協力して科学発見プロセスを実現するために、事前に、または発見プロセス中にAIの支援を受けて、革新的な新しい物理的概念を創造する必要もあります。
4 機械が人間には未知、あるいは理解できない独自の内部的な「意味」を持っているかどうかについては議論があることは承知していますが、本論文では人間のための科学的発見を目指しているため、この点は焦点ではありません。
上記の実験では、Explainable AI が方程式 \(r^3\omega^2=c\) (\(c\) は定数) を生成したら、まず \(a=r\omega^2\) が円運動における求心加速度を意味することを理解する必要があります。求心加速度 \(a\) の導出には微積分は必要ありませんが、加速度はケプラーの時代にはまだ新しい概念であり、確立される必要がありました。この新しい概念を用いることで、\(r^3\omega^2=c\) は \(ar^2=c\)、つまり \(a ∝ \frac{1}{r^2}\) に再構成でき、これが求心加速度方程式となります。求心加速度方程式 \(a ∝ \frac{1}{r^2}\) は、火星の軌道が楕円形である理由を説明できますが、楕円軌道の原因を本当に知るには、求心加速度 a の原因、つまり火星をそのような軌道に回す根本的な「力」が何であるかを知る必要があります。
ケプラーの時代には、科学者たちはすでに力の概念を持っていましたが、力の正しい働きを理解していませんでした。なぜなら、力は距離、ひいては速度に比例すると考えていたからです。ニュートンの偉大さは、力が速度の理由ではなく、実際には加速の理由であることを理解したことでした。そして、彼は力と加速を\(F=ma\)によって革新的に結び付けました。これに基づき、\(M\)を太陽の質量とすると、\(ar^2 =c\)は\(Mar^2=Mc\)と整理でき、\(Fr^2=Mc\)となり、\(F ∝ \frac{1}{r^2}\)となり、ニュートンの万有引力の逆二乗の法則が導き出されます。この解釈のプロセスにおいて、人間は物理学の概念を理解したり創造したりする上で、依然として重要な役割を果たす必要があることがわかります。これは、ケプラーとニュートンの時代には力の測定がほぼ不可能だったため、観測データに力 \(F\) が変数として含まれていなかったことが一因です。もし力 \(F\) が時間 \(t\) や角度 \(\theta\) のように観測値を持つ変数の1つであったなら、(説明可能な)AI手法は、他の変数の場合と同様に、データから \(F\) の記号式を抽出できたかもしれません。これにより、発見プロセスにおける人間による探索、介入、解釈、そして創造の労力を節約できます。しかし、多くの現代の科学データセットのように \(F\) 値を観測できたとしても、人間の専門家が観測データにまだ存在しない新しい概念を革新的に創造する必要がある可能性を完全に排除することはできません。
式(4)で発見された規則\(r^3\omega^2=c\)は、円運動に\(\bar{\omega}=\frac{2\pi}{T}\)を適用すると、ケプラーの第三法則\(\frac{\bar{r}^3}{T^2}=c^\prime\)と誤って解釈される可能性があります。実際には、式(4)はケプラーの第三法則として解釈すべきではありません。なぜなら、ケプラーの第三法則は太陽を周回するすべての惑星に適用される普遍的な規則を述べているのに対し、式(4)は火星のデータのみから導かれた規則であるため、火星にのみ適用される規則を述べているからです。より具体的には、式(4)は、任意の時刻\(t\)において、火星の角速度\(ω\)とそれに対応する太陽までの距離\(r\)が定数則を満たすことを述べています。一方、ケプラーの第三法則は、太陽を周回するすべての惑星について、太陽までの平均距離と公転周期が定数則を満たすことを述べています。ケプラーの第三法則を真に発見し、正当化するには、より多くの惑星のデータを含める必要があります。実際、ケプラー自身は水星、金星、地球、火星、木星、土星の6つの惑星を研究しました。 この例は、Explainable AIが発見したルールを解釈する際には、結果を過度に一般化することを避けるため、細心の注意を払う必要があることを示しています。
しかし、式(4)は依然として有用であり、ケプラーの第三法則への示唆を与える可能性があります。この式をマクロな視点から見ると、周期\(T\)は角速度\(\omega\)の積分効果と見なすことができ、\(T\)と\(r\)も同様の規則性を示すかどうかを検討することにつながる可能性があります。ケプラーの第三法則\(\frac{\bar{r}^3}{T^2}=c^\prime\)の正当性を証明するには他の惑星の情報が必要であることは分かっていますが、火星のデータのみから導かれる式(4)は正しい方向を示し、発見プロセスを加速させる可能性があります。実際、\(\bar{\omega}=\frac{2\pi}{T}\) を式(4)に代入すると、\(\frac{\bar{r}^3}{T^2}=\frac{c}{4\pi^3}=7.56086×10^{-6}AU^3day^{-2}\overset{\cdot}{=}c^\prime\) となり、これはケプラーの結果 (\(7.5\times 10^{-6}AU^3day^{-2}\)、誤差0.82%以内) や現代科学の結果 (\(7.495×10^{-6}AU^3day^{-2}\)、誤差0.88%以内) に近い値となります。直感によってマクロとミクロの視点を関連付ける能力は、現在のAIではなく人間に特有のものであり、これが人間が現代の科学発見プロセスにおいて依然として不可欠な役割を果たしている理由の一つです。
本稿では、科学的発見のための説明可能なAIに基づくパラダイムを示すことにより、科学的発見における説明可能なAIの役割を強調する。このアイデアを実証するために、16世紀から17世紀にかけて科学革命を牽引したティコ・ブラーエの天文観測データの少量に基づき、説明可能なAIの支援により、ケプラーの惑星運動の法則とニュートンの万有引力の法則がどのように再発見されるかを示す。技術的には、予測とデータ拡張にはディープニューラルネットワークなどのブラックボックスモデルを用い、モデルの説明にはシンボリック回帰などのホワイトボックスモデルを用いる。説明可能なAIの支援の下で結果を解釈することにより、洞察に満ちた発見と結論を導き出すことができる。また、科学の発見プロセスにおいて、新しい概念の創造、発見された変数や規則への意味の付与、そしてAIベースの発見プロセスを監督するための洞察力に富んだ直感の提供といった、人間が不可欠な役割を果たすことも示します。
今後、私たちは、ブラックボックスモデルとホワイトボックスモデルをより広範囲に検討し、様々な科学分野に適用することで、説明可能なAIに基づく科学的発見のパラダイムをさらに洗練させていきます。また、このフレームワークを、現代の天文観測データに基づく暗黒物質や、大型ハドロン衝突型加速器から収集されたデータに基づく素粒子物理学など、より最先端の科学的問題にも活用し、人類が知らない新たな知識の発見を目指します。そしておそらくいつの日か、私たちは常に巨人の肩の上に立っているため、AIに説明を求めることでプロセスを完全に制御しながら、AI自身が発見した知識を通じて説明可能なAIの性能を向上させることができるでしょう。
このセクションでは、論文で参照されているすべての表と図を紹介します。